PHPでTwitterのOAuth認証でログインするサイトのサンプルページを作って見ました。実行内容は、次の通りです。
.htaccess を使ってすべてのアクセスを index.php に渡す。index.php でログイン済みかどうかをチェック。ログインしていない場合、template.php を使って状況に応じたメッセージを表示。「ログイン」をクリックしたら、Twitterの認証ページヘリダイレクト。認証がすんだら page_1.php を開く。あとは自由にページを見られる。存在しないページをリクエストされたら、404.php を表示する。「ログアウト」をクリックしたらログアウトする。
PHPでTwitterのOAuth認証を使ってログインするサイトのサンプルページを作って見ました。
http://php-oauth-sample.dwm.me/
作ったファイルは、.htaccess と index.php、page_1.php、page_2.php、404.php、それから template.php です。
ファイルはhttp://php-oauth-sample.dwm.me/twitter_oauth_sample.zip からダウンロードできます。
実行内容は、次の通りです。
- .htaccess を使ってすべてのアクセスを index.php に渡す。
- index.php でログイン済みかどうかをチェック。
- ログインしていない場合、template.php を使って状況に応じたメッセージを表示。
- 「ログイン」をクリックしたら、Twitterの認証ページヘリダイレクト。
- 認証がすんだら page_1.php を開く。
- あとは自由にページを見られる。(他には page_2.php しかありませんけど)
- 存在しないページをリクエストされたら、404.php を表示する。
- 「ログアウト」をクリックしたらログアウトする。
page_1.php と page_2.php それから 404.php は独立していて、それ以外の処理を template.php に渡して表示します。
また、ライブラリとして https://github.com/abraham/twitteroauthで公開されている twitteroauth を使っています。(上に書いた圧縮ファイルの http://php-oauth-sample.dwm.me/twitter_oauth_sample.zip には同梱していません)
Twitter Apps で認証キーを取得する
まずはじめにTwitter Apps(https://apps.twitter.com/)で、API key と API secret を取得します。
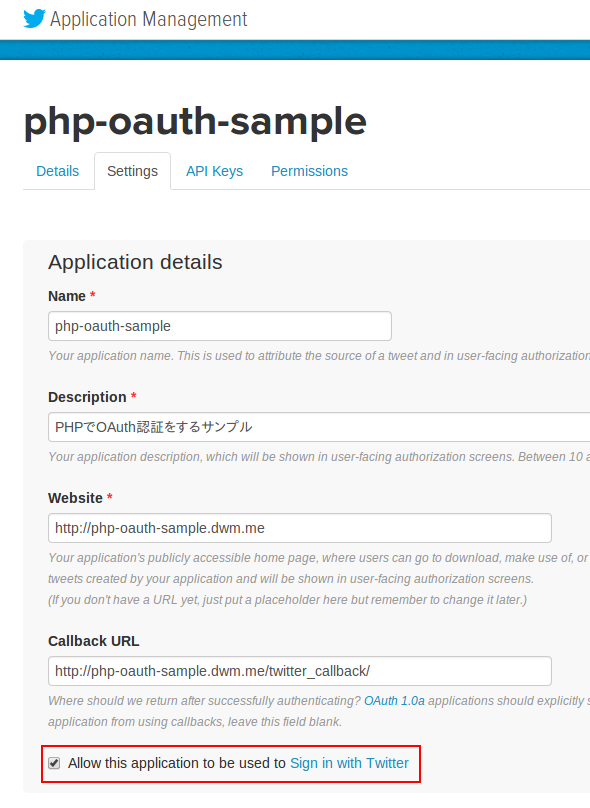
Website と書かれた項目と Callback URL と書かれた項目以外は、好きに書いて構いませんが、認証画面で次のように表示されます。
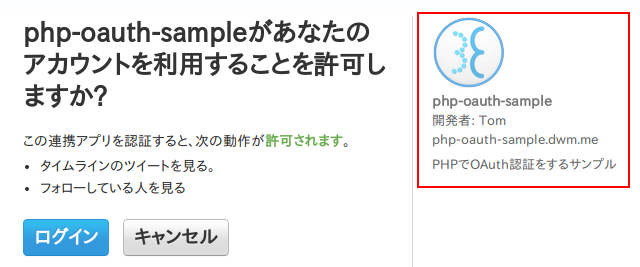
Website には、認証させるサイトのURLを入力します。
Callback URL は、認証が済んだ後に自動でリダイレクトされる先のURLです。私のサンプルでは http://php-oauth-sample.dwm.me/twitter_callback/ になっていますが、ここで必要なデータを取得したら、再びリダイレクトして http://php-oauth-sample.dwm.me/page_1/ に飛ばしています。結果として、ログインしたユーザーが最初に見るのは http://php-oauth-sample.dwm.me/twitter_callback/ ではなく http://php-oauth-sample.dwm.me/page_1/ になります。
また、Twitter Apps に登録する際に注意しなくてはいけないのが、Allow this application to be used to Sign in with Twitter という部分です。ここにチェックを入れておかないと、ログインする度に認証ページが開いてしまいます。
ここにチェックをいれておけば、最初の認証以外は、すぐに http://php-oauth-sample.dwm.me/twitter_callback/ へリダイレクトさせることが出来ます。その説明は次のページが詳しいです。
PHPで「Sign in with Twitter」を実装する方法 – 頭ん中
同ページより引用
- ユーザーが呼び出し元アプリケーションを承認している場合
- ユーザーが Twitter にログインしている場合:直ちに承認されて、呼び出し元のアプリケーション(callback URL)にリダイレクトされる。
- ユーザーが Twitter にログインしていない場合:Twitter のログイン画面が表示され、ログイン後は直ちに承認されて、呼び出し元のアプリケーションにリダイレクトされる。
- ユーザーがまだ呼び出し元アプリケーションを承認していない場合、あるいは承認を取り消している場合
- ユーザーが Twitter にログインしている場合:OAuth の承認画面が表示され、承認後は呼び出し元のアプリケーションにリダイレクトされる。
- ユーザーが Twitter にログインしていない場合:まず Twitter のログイン画面が表示され、ログイン後に OAuth の承認画面に移り、承認後は呼び出し元のアプリケーションにリダイレクトされる。
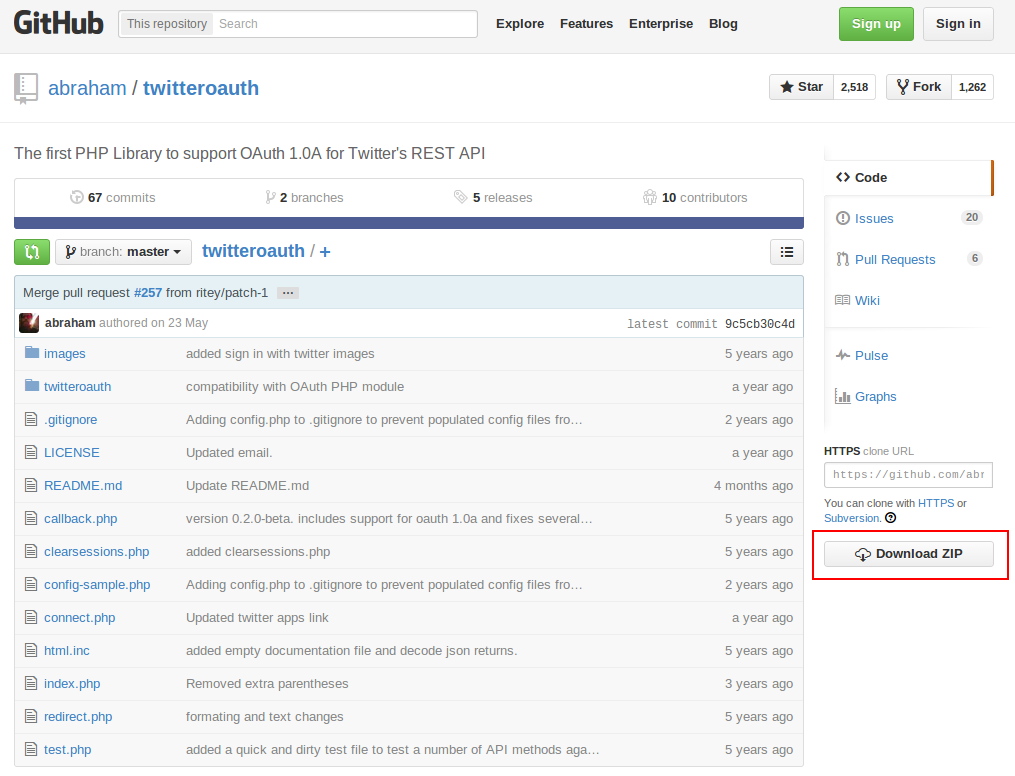
ライブラリ twitteroauth の取得
OAuth認証をするために使うライブラリを https://github.com/abraham/twitteroauth から取得します。
開いたページの右側に Download ZIP というボタンがあるので、それをクリックするとダウンロードできます。
ダウンロードした .zip ファイルを解凍するとファイルがたくさんありますが、必要なのは twitteroauth というフォルダだけです。このフォルダの中に入っている2つのファイル OAuth.php と twitteroauth.php を使います。
.htaccess の作成
この項目は私のやった方法の場合で、OAuth認証と基本的に無関係です。
サイトへの、すべてのリクエストを index.php に渡して、そこで処理するために次の内容の .htaccess を用意しました。
<IfModule mod_rewrite.c>
RewriteEngine On
RewriteBase /
RewriteRule . index.php [QSA,L,PT]
</IfModule>
実際の .htaccess には他にもいろいろ書いていますが、mod_rewrite に必要なところだけ書き出しています。これで、すべてのアクセスは index.php に渡されるので、そこで処理をします。
URLは http://php-oauth-sample.dwm.me/page_1/ という形式で、この場合だと page_1.php を読み込んで表示するようにします。
index.php の内容
大きく分けると switch 文で、次のように処理を振り分けています。
実際に使っているファイルは http://php-oauth-sample.dwm.me/twitter_oauth_sample.zip からダウンロードできますので、そちらを参照してください。
switch($match[1]){
// ログインをリクエストされた場合
case TWITTER_LOGIN:
// 認証用のtokenを取得
if(token が取得できたら){
// Twitter へリダイレクトして終了
//(認証後、登録したリダイレクトページに返ってくる)
return;
}
// token が取得できなければ、表示するメッセージを用意してbreak
break;
// Twitterの認証画面からリダイレクトされてきた場合
case TWITTER_CALLBACK:
if(認証されていたら){
// 送られたデータをセッションに渡し
// http://php-oauth-sample.dwm.me/page_1/ ヘ リダイレクトして終了
return;
}
// 認証されなていなければ、表示するメッセージを用意してbreak
break;
// ログアウトをリクエストされた場合
case LOGOUT:
// セッションをクリア
// ログアウト完了のメッセージを用意してbreak
break;
// その他のケース
default:
if(指定のページが存在する場合){
if(ログインしていれば){
// そのページを表示して終了
return;
}
// ログインしていなければ、ログインを促すメッセージを用意
}else{
// ページが存在しなければ 404ページを読み込んで終了
return;
}
// 指定のページが存在するけど、ログインしていない場合はbreak
break;
}
// ここまでで return していなければ
// template.php に用意したメッセージを埋め込んで表示
header('Content-Type: text/html; charset=UTF-8');
require_once(TEMPLATE_FILE);
ログインをリクエストされた場合
// API key と API secret は https://dev.twitter.com/apps から取得する
define('API_KEY', '*************************');
define('API_SECRET', '**************************************************');
define('LOCATION_BASE', 'http://php-oauth-sample.dwm.me');
define('TWITTER_CALLBACK', 'twitter_callback'); // Twitterからのコールバックページ
/************************************************************************/
// switch文から該当部分のみ抜粋
case TWITTER_LOGIN:
// token を取得
$auth = new TwitterOAuth(API_KEY, API_SECRET);
$url = sprintf('%s/%s/', LOCATION_BASE, TWITTER_CALLBACK);
$token = $auth->getRequestToken($url);
// token が取得できたら Twitter へリダイレクトして終了
//(認証後、登録したリダイレクトページに返ってくる)
if(isset($token['oauth_token']) && isset($token['oauth_token_secret'])){
// セッションに登録
$_SESSION['oauth_token'] = $token['oauth_token'];
$_SESSION['oauth_token_secret'] = $token['oauth_token_secret'];
// 2つ目の引数が true だと
// アプリケーションを承認済みユーザーは即座にcallbackページにリダイレクト
// 未登録の場合は、承認画面を表示後、承認が終わるとリダイレクトされる
// ただし、Twitter Apps で
// Allow this application to be used to Sign in with Twitter
// にチェックを入れておく事が必要
$auth_url = $auth->getAuthorizeURL($_SESSION['oauth_token'], true);
header("Location: " . $auth_url);
return;
}
// token が取得できなければ、表示するメッセージを用意してbreak
$message = 'エラーが発生しました。恐れ入りますが、もう一度やり直してください。';
break;
Twitterの認証画面からリダイレクトされてきた場合
case TWITTER_CALLBACK:
// 認証されていたら
if(isset($_REQUEST['oauth_verifier']) && ('' != $_REQUEST['oauth_verifier'])){
$auth = new TwitterOAuth(API_KEY, API_SECRET,
$_SESSION['oauth_token'], $_SESSION['oauth_token_secret']);
$access_token = $auth->getAccessToken($_REQUEST['oauth_verifier']);
$_SESSION['user_id'] = $access_token['user_id'];
$_SESSION['screen_name'] = $access_token['screen_name'];
// ログイン後、最初に表示するページヘリダイレクトして終了
// URLにGETで oauth_token と oauth_verifier が含まれているので
// それを消すために require でファイルを読むのではなくリダイレクトさせる
// define('FIRST_PAGE', '/page_1/');
header('Location: ' . LOCATION_BASE . FIRST_PAGE);
return;
}
// 認証されなければ、表示するメッセージを用意してbreak
$message = 'ログイン出来ません。Twitterアカウントを確認してください。';
// 認証されていなければセッションの削除
session_destroy();
unset($_SESSION);
break;
ログアウトをリクエストされた場合
case LOGOUT:
// ログアウト完了のメッセージを用意
$message = 'ログアウトしました。';
// セッションの削除
session_destroy();
unset($_SESSION);
break;
閲覧用のページが指定された場合
default:
// define('FILE_PATTERN', FILES_PATH . '/files/%s.php');
// .php ファイルは FILES_PATH/files/ にある
$path = sprintf(FILE_PATTERN, $match[1]);
// 指定のページが存在する場合
if(file_exists($path)){
// ログインしていれば
if(isset($_SESSION['user_id'])){
// そのページを表示して終了
header('Content-Type: text/html; charset=UTF-8');
require_once($path);
return;
}
// ログインしていなければ、ログインを促すメッセージを準備
$message = sprintf('%sをご覧になるにはログインが必要です。', $match[1]);
}else{ // 指定のページが存在しない場合
// ページが見つからない404ページを読み込んで終了
header('HTTP/1.0 404 Not Found');
$file_404 = sprintf(FILE_PATTERN, PAGE_404);
require_once($file_404);
return;
}
break;
大体、このような流れで処理しています。
動作はデモページ http://php-oauth-sample.dwm.me/ でご確認ください。
実際のファイルはhttp://php-oauth-sample.dwm.me/twitter_oauth_sample.zip からダウンロードできます。(ライブラリの twitteroauth は同梱していません)