昨日の夜書いた、このブログの記事ですが、公開後はGoogle検索に載っていたのに、今日の15:00頃、調べたら除外されていました。今はまた復活しています。
復活するまでにやったことを時系列に沿って書きますが、正直有効なデータとなり得るかはわかりません。というのは、前にやった作業が反映されないうちに、次の対応をした可能性もあり、回復した直前の作業が効いたのか、それ以前の処理が作用したのか判断つきかねるからです。もしかしたら、私がやったことは無関係で、一時的な現象だった可能性もあります。
ということで、今回は起こったこと、やったことを、時系列に沿って、書き残すだけにします。
昨夜書いた記事
昨夜書いた記事は「ミラクルフルーツはどこにある?」です。公開後、Googleにインデックスされているか確認して、検索したらちゃんと書いた記事が表示されました。
昨日のテレビで扱われたようですので、急いで記事にしたんですが、その時公開したのは目次にある4項目中の、最初の3つだけです。4項目めは今朝追加しました。
というのも、実はきのうまでミラクルフルーツというものを、私は知らなかったのです。知らなかったから面白くて記事にしたというのがあります。ところが、今朝わかったのですが、それは15年以上前にもブームになっていたようです。知らずに記事にしたものだから、冒頭は「今ミラクルフルーツというのがブームらしい!」という書き出しでした。
そして今朝、次の記事を見つけます
「ミラクルフルーツ と 宇多田ヒカル」
この記事、面白いです。ただ、それを読んではじめて15年以上も前にミラクルフルーツが流行っていた事を知ります。そうなると恥ずかしいのが昨夜の記事の冒頭「今ミラクルフルーツというのがブームらしい!」です。
「うげっ。やべぇ!」ということで、速攻で記事の冒頭を、そしらぬ顔して書き直しました。同時に目次の4項目めを追加して、記事の最後に「ミラクルフルーツ と 宇多田ヒカル」へのリンクと紹介を加えました。もちろん、以前ブームだった事を私が知らなかったのは内緒です。
その直後10時にファンブログのメンテナンスが始まる
「なんで定期メンテナンスを日中やるの!夜でしょ?」(普通は深夜)などということは、今回は無視します。10時から11時までがメンテナンスだったことだけ、ご記憶ください。
15時頃、昨夜の記事が検索出来ないことに気づく。
実は、この直前にひとつ記事を公開しました。それは「バンダイのスマートパンツを通販で買う! – 税込300円から」です。
昨夜と同じように、公開した新しい記事がGoogleに登録されているか確かめます。登録されていました。しかし、その時ついでに検索した昨夜の記事が出てきません。
ここまでが前置きで以下、行なった対処です。
インデックスされているかを確かめる
検索フォームに「site:fanblogs.jp ミラクルフルーツはどこにある?」と入れて検索した結果が次のキャプチャです。
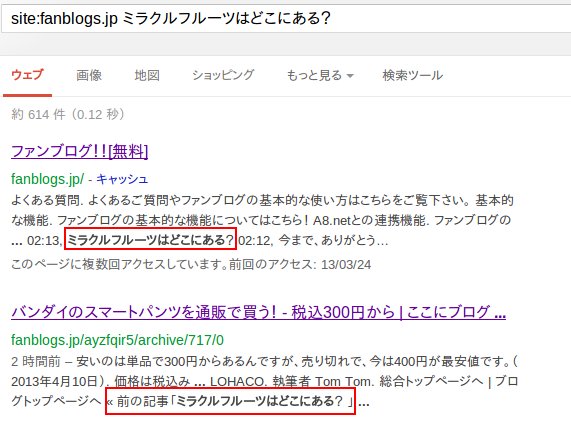
本来、いちばん最初に来るはずの記事「ミラクルフルーツはどこにある?」が表示されません。
最初に出てきたファンブログ!![無料]は、このブログを書いているファンブログのトップページです。そこに記事のタイトルがあるのは、最新記事一覧がトップページにあるからで、昨夜「ミラクルフルーツはどこにある?」を公開したすぐ後でクロールされたようです。
2番目に「バンダイのスマートパンツを通販で買う! – 税込300円から」が表示されているので、このブログがインデックスから削除されたわけではないです。しかも、その「前の記事」で「ミラクルフルーツはどこにある?」と書いてある。タイトルにも問題はないようです。
次に検索フォームに、記事のURLだけを「http://fanblogs.jp/ayzfqir5/archive/716/0」と入力して検索しましたが、記事は出てきませんでした。
記事を再投稿した直後にメンテナンスがあった
記事を再投稿したときに更新Pingも送られたわけですが、その直後にメンテナンスがありました。メンテナンス中は管理画面だけでなく、ブログも閲覧出来なくなります。そのタイミングでクローラーが来たとしたら、エラーになります。
それが原因の可能性はないだろうか?そう思って、もう一度ファンブログの管理画面を開き、改めて記事を投稿しました。これで、更新Pingもまた撃たれました。
反映されるまで少し待ちます。メンテナンスが予定通りに終わっていたなら、ブログが見られなかったのは1時間だった。と、いうことで1時間待ってみます。
1時間後、やはり検索されなかった
1時間後、もう一度検索してみましたが表示されません。今度はGoogle ウエブマスターツールにログインします。
まず試しにサイトマップを再送信してみました。5分後確認しましたが、検索結果に表示されません。そこで、ダッシュボードの健全性にある「Fetch as Google」というのを試してみます。
実は「Fetch as Google」というのが、どういう機能なのかわからず、今まで使ったことがありませんでした。今回、対処法を検索しているうちに、「パシのSEOブログ」さんにある「Googleからインデックス削除された場合の確認手順」という記事を見つけました。この記事は非常に有用で大変な参考になります。
その記事中に次のように書いてあります。
Fetch as Googleでは、実際にそのURLにクローラーがアクセスできるのかという確認と、そのURLをインデックスしてもらえるようにお願いすることができます。
それならと思って試してみます。
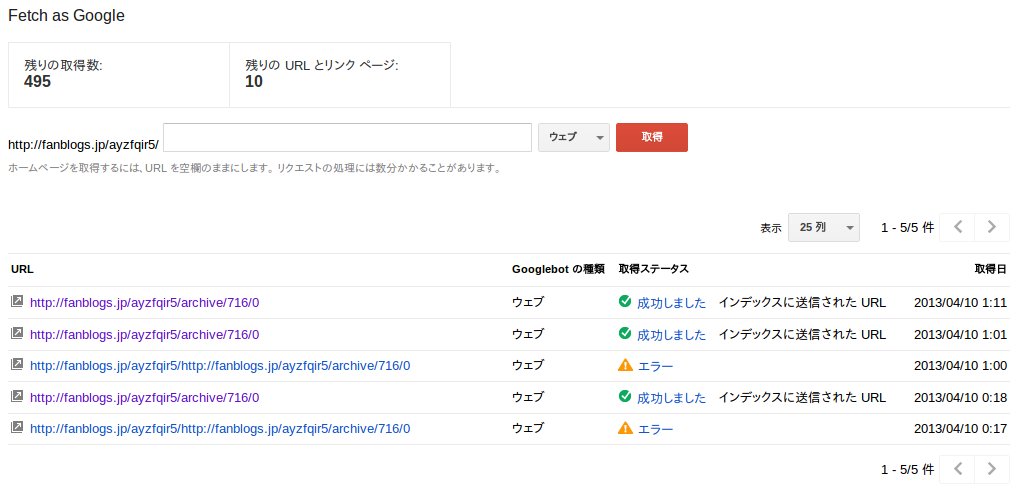
これエラーが2つあるのは、私が間違えてURLをフルパスで入れたためです。フォームの左にトップディレクトリのURLが表示されていますが、記入するのはトップからの相対パスです。
「成功しました」が3つあります。3回作業を行ないました。
1回目は、なにも処理をせず、とにかくURLを打ち込んで、取得ボタンを押しました。その後、検索してみますが、結果に反映されません。
昨夜の状態に戻してみる
原因がわからないのだから、よかった時の状態に戻してみよう。ということで、今朝追加した部分を削除します。同時に「ミラクルフルーツ」というキーワードが、多すぎるのがいけないかもと思い、目次も削除します。
記事の最後と目次を削除して、ブログを保存。それで5分待ってから、検索しますが結果は変わりません。そこで、もう一度「Fetch as Google」を実行しますが、効果なし。
再び追記部分を戻す
検索結果に反映されないので削除した部分を元に戻します。そして、記事のソースを確認。実は私、よく隠れstrongというのをやります。つまり、下のようなソースです。
<strong style=”font-weight:normal;”>強調したい文章</strong>
これが嫌われたのだろうか?と思いながら、それを削除しようとしました。ソースをよく見ると、下のようになっています。タグが1個足りない。
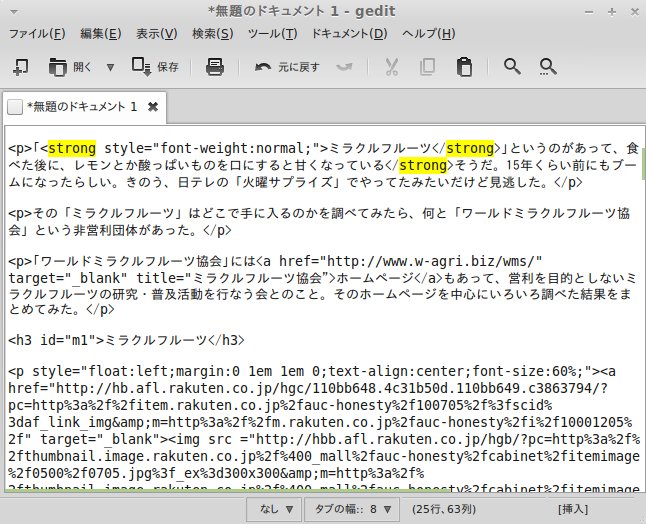
キャプチャ画面で見ると2行目に相当する場所ですが、本来は下のようにするつもりでした、その赤字の部分、開始タグがありません。
<strong style=”font-weight:bold;”>レモンとか酸っぱいものを口にすると甘くなっている</strong>そうだ。
これは今朝「今ミラクルフルーツというのがブームらしい!」という文から書き換えた場所です。普段はエディタで書いたものをコピーして投稿しているんですが、今朝は面倒だったので、管理パネルの狭いフォームで直接修正しました。その場所です。
そのHTMLを修正して、ブログに再投稿。ソースにエラーがあったのだから、試しにと思って、3回目の「Fetch as Google」を行ないます。
そして、すぐに検索。「Fetch as Google」を実行してから1分も経っていないのに、検索結果に現れました。
以上、時系列に沿った報告です。正直なところHTMLのミスが原因で検索されなくなったのかは、私自身、懐疑的です。参考になるのかどうかはわかりませんが、記録として残しておきます。